自动摘要
正在生成中……
平均负载,是衡量一个系统整体负载情况的关键指标,在日常监控中我们经常会使用到它。因此,我们有必要花多一些功夫去理解它。
查看系统平均负载
查看系统平均负载的方法有很多,通常使用较多的命令是uptime和top。
$ uptime
20:02:53 up 1 day, 11:56, 5 users, load average: 1.00, 1.01, 1.04
输出结果中load average即为系统平均负载,对应于top命令输出的第一行。
$ top
top - 20:02:54 up 1 day, 11:56, 5 users, load average: 1.00, 1.01, 1.04
...
另外,还可以直接查看/proc/loadavg
$ cat /proc/loadavg
1.04 0.40 0.22 3/222 24411
其中,前3个值为平均负载,与uptime、top的输出结果中load average对应。
遇到任何不明白的地方,第一步通常是通过man命令查看手册来解决。man的输出内容,一般会有比较详尽的解释。
另一个好处是,由于相同命令在不同版本的Linux上的用法和输出可能有所差异,在当前系统通过man查看能得到更一致的解释。
以下是对uptime输出各项,从左到右的含义说明:
$ man uptime
The current time, how long the system has been running, how many users are currently logged on, and the system load averages for the past 1, 5, and 15 minutes.
当前时间、系统运行了多长时间、当前登录了多少用户以及过去1分钟、5分钟和15分钟的系统平均负载。
理解系统平均负载
$ man uptime
System load averages is the average number of processes that are either in a runnable or uninterruptable state. A process in a runnable state is either using the CPU or waiting to use the CPU. A process in uninterruptable state is waiting for some I/O access, eg waiting for disk. The averages are taken over the three time intervals. Load averages are not normalized for the number of CPUs in a system, so a load average of 1 means a single CPU system is loaded all the time while on a 4 CPU system it means it was idle 75% of the time.
系统平均负载指是处于可运行状态和不可中断状态的进程的平均数量。
即单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和 CPU 使用率并没有直接关系。
- 可运行状态的进程,包括正在使用CPU的进程,和正在等待CPU的进程。
- 对应于ps命令输出的STAT列中状态为R的进程。
- 状态R:running or runnable (on run queue)
- 不可中断状态的进程,表示正在等待其它系统资源的进程,例如等待磁盘I/O。
- 对应于ps命令输出的STAT列中状态为D的进程。
- 状态D:uninterruptible sleep (usually IO)。
- 不可中断状态实际上是系统对进程和硬件设备的一种保护机制。比如,当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的。
因此,在平均负载把不可中断状态的进程考虑进去之后,我们称之为系统平均负载或Linux平均负载,而不是CPU平均负载。
查看进程的所有状态
$ man ps
输入查找:/PROCESS STATE CODES,显示所有进程的状态码如下。
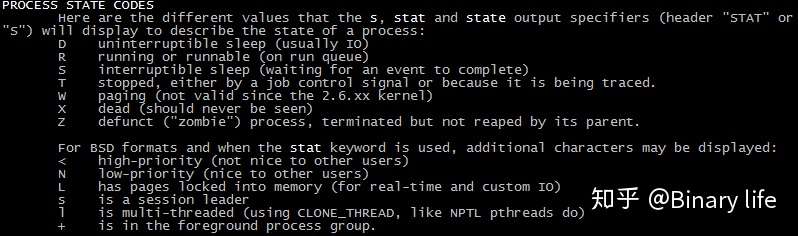
其中,R、D状态对应于可运行和不可中断两个状态。
1分钟、5分钟、15分钟
解释一:
- 如果平均负载为0.0,则表示系统处于空闲状态。
- 如果1分钟的平均值高于5分钟或15分钟的平均值,则表示负载正在增加。
- 如果1分钟的平均值低于5或15分钟的平均值,则表示负载正在减少。
- 如果平均负载高于系统的CPU数量,那么系统可能会遇到性能问题。
解释二:
- 如果 1 分钟、5 分钟、15 分钟的三个值基本相同,或者相差不大,那就说明系统负载很平稳。
- 但如果 1 分钟的值远小于 15 分钟的值,就说明系统最近 1 分钟的负载在减少,而过去 15 分钟内却有很大的负载。
- 反过来,如果 1 分钟的值远大于 15 分钟的值,就说明最近 1 分钟的负载在增加,这种增加有可能只是临时性的,也有可能还会持续增加下去,所以就需要持续观察。一旦 1 分钟的平均负载接近或超过了 CPU 的个数,就意味着系统正在发生过载的问题,这时就得分析调查是哪里导致的问题,并要想办法优化了。
例如,对于单个CPU系统上的平均负载为"1.73 0.60 7.98",表示:
- 在最后1分钟内,系统平均过载73%((1.73-1)/1)。
- 在最近5分钟内,系统平均负载不高,还有空闲。
- 在最后15分钟内,系统平均过载为698%((7.98-1)/1)。
如果平均负载为2,在只有1个CPU的系统中,那么有一半的进程可能竞争不到CPU。
因此,一般比较理想的情况,是每个CPU上面运行着一个进程。(不是绝对的)
平衡负载多少正常
当平均负载高于 CPU 数量 70% 的时候,你就应该分析排查负载高的问题了。一旦负载过高,就可能导致进程响应变慢,进而影响服务的正常功能。
对于具有多个CPU的系统,通常可以先将平均负载除以处理器数量。然后再通过查看CPU的使用率、IO等待、上下文切换等进行排查问题。
平均负载与 CPU 使用率
既然平均负载代表的是活跃进程数,那平均负载高了,是不是就意味着 CPU 使用率高了?
回顾一下,平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数。所以,它不仅包括了正在使用 CPU 的进程,还包括等待 CPU 和等待 I/O 的进程。
而 CPU 使用率,是单位时间内 CPU 繁忙情况的统计,跟平均负载并不一定完全对应。比如:
- CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;
- I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高;
- 大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
关于中断睡眠的2个状态
S (TASK_INTERRUPTIBLE),可中断的睡眠状态
处于这个状态的进程因为等待某某事件的发生(比如等待socket连接、等待信号量),而被挂起。这些进程的task_struct结构被放入对应事件的等待队列中。当这些事件发生时(由外部中断触发、或由其他进程触发),对应的等待队列中的一个或多个进程将被唤醒。
通过ps命令我们会看到,一般情况下,进程列表中的绝大多数进程都处于TASK_INTERRUPTIBLE状态(除非机器的负载很高)。毕竟CPU就这么一两个,进程动辄几十上百个,如果不是绝大多数进程都在睡眠,CPU又怎么响应得过来。
D (TASK_UNINTERRUPTIBLE),不可中断的睡眠状态
与TASK_INTERRUPTIBLE状态类似,进程处于睡眠状态,但是此刻进程是不可中断的。不可中断,指的并不是CPU不响应外部硬件的中断,而是指进程不响应异步信号。绝大多数情况下,进程处在睡眠状态时,总是应该能够响应异步信号的。否则你将惊奇的发现,kill -9竟然杀不死一个正在睡眠的进程了!于是我们也很好理解,为什么ps命令看到的进程几乎不会出现TASK_UNINTERRUPTIBLE状态,而总是TASK_INTERRUPTIBLE状态。
而TASK_UNINTERRUPTIBLE状态存在的意义就在于,内核的某些处理流程是不能被打断的。如果响应异步信号,程序的执行流程中就会被插入一段用于处理异步信号的流程(这个插入的流程可能只存在于内核态,也可能延伸到用户态),于是原有的流程就被中断了。(参见《linux内核异步中断浅析》)在进程对某些硬件进行操作时(比如进程调用read系统调用对某个设备文件进行读操作,而read系统调用最终执行到对应设备驱动的代码,并与对应的物理设备进行交互),可能需要使用TASK_UNINTERRUPTIBLE状态对进程进行保护,以避免进程与设备交互的过程被打断,造成设备陷入不可控的状态。这种情况下的TASK_UNINTERRUPTIBLE状态总是非常短暂的,通过ps命令基本上不可能捕捉到。
模拟不可中断的睡眠状态
使用stress-ng来模拟压力,对于CentOS,CentOS 7才支持stress-ng。

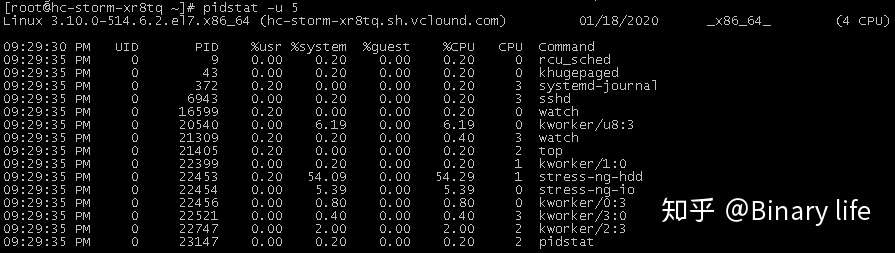
使用ps命令查看进程状态:

可以看到,其中22454的进程状态为不可中断的睡眠状态D+。(经过测试,可以kill掉,这里留个问号)
使用vmstat验证一下:

第二列b的数量为1,b(Blocked)表示处于不可中断睡眠状态的进程数。而第一列r(Running or Runnable)是就绪队列的长度,也就是正在运行和等待 CPU 的进程数。
1分钟的平均负载为2.29:

查看mpstat的结果,内核态sys占20.51%,IO等待占19.66,CPU整体空闲率将近60%。(4核)
再用平均负载计算一下,2.29/4=57%,实际的CPU使用率却并没有这么高,验证了前面提到的平均负载高并不意味着CPU使用率高。

系统有多少个CPU
$ grep "model name" /proc/cpuinfo | wc -l
$ lscpu | grep '^CPU(s)'
或者执行top命令,然后按数字1,可以看到Cpu0~CpuN,共N+1个CPU。
相关工具
vmstat
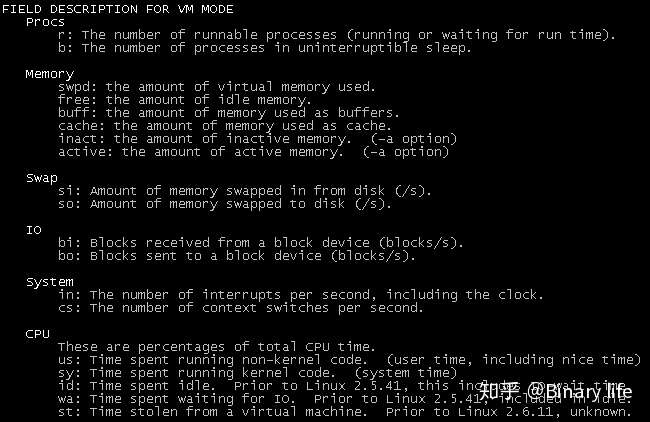
Report virtual memory statistics
vmstat 是一个常用的系统性能分析工具,主要用来分析系统的内存使用情况,也常用来分析 CPU 上下文切换和中断的次数。几个重要的列:
- cs(context switch)是每秒上下文切换的次数。
- in(interrupt)则是每秒中断的次数。
- r(Running or Runnable)是就绪队列的长度,也就是正在运行和等待 CPU 的进程数。
- b(Blocked)则是处于不可中断睡眠状态的进程数。
mpstat
Report processors related statistics.
mpstat 是一个常用的多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标,以及所有 CPU 的平均指标。
监控所有CPU
-P ALL
根据编号监控指定CPU
-P 0,1,2...
监控所有CPU,每间隔5秒后输出一组数据
$ mpstat -P ALL 5

pidstat
Report statistics for Linux tasks.
pidstat 是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标。
默认显示进程的CPU信息,相当于pidstat -u。
查看CPU使用情况
-u Report CPU utilization.
$ pidstat -u 5
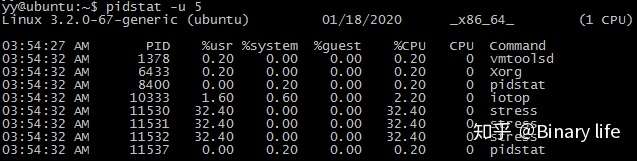
输出列说明:
- 用户态 CPU 使用率 (%usr);
- 内核态 CPU 使用率(%system);
- 运行虚拟机 CPU 使用率(%guest);
- 等待 CPU 使用率(%wait);
- 总的 CPU 使用率(%CPU)。
查看进程上下文切换情况
-w Report task switching activity (kernels 2.6.23 and later only).
$ pidstat -w 5
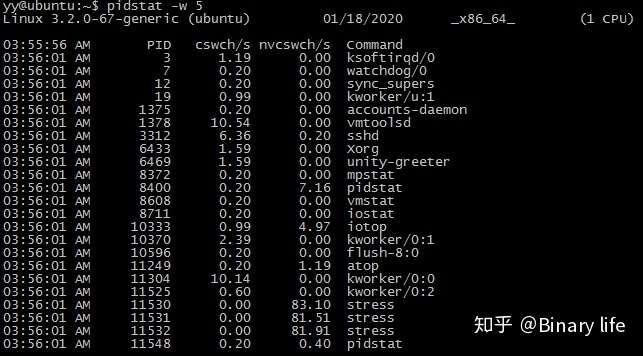
- cswch列:表示每秒自愿上下文切换(voluntary context switches)的次数。
- nvcswch:表示每秒非自愿上下文切换(non voluntary context switches)的次数。
这两个概念很重要,它们意味着不同的性能问题:
自愿上下文切换,是指进程无法获取所需“资源”,导致的上下文切换。比如说,I/O、内存等系统资源不足时,就会发生自愿上下文切换。
非自愿上下文切换,则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换。
查看线程上下文切换情况
-t Also display statistics for threads associated with selected tasks.
$ pidstat -wt 5
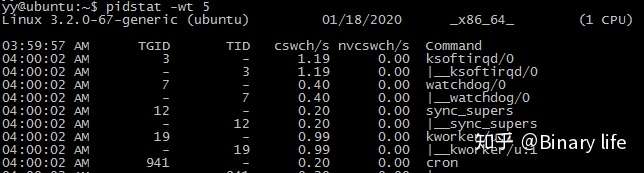
注意,-w是必须的,否则显示不了上下文切换信息。
增加-t参数后,输出结果多显示了两列,线程组TGID和线程TID。
小结
平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数。
- 平均负载高有可能是 CPU 密集型进程导致的;
- 平均负载高并不一定代表 CPU 使用率高,还有可能是 I/O 更繁忙了;
- 当发现负载高的时候,你可以使用 mpstat、pidstat 等工具,辅助分析负载的来源。
- 查看系统平均负载:uptime、top、/proc/loadavg
- 查看每个CPU使用率:top、mpstat -P ALL 5
- 查看每个进程的CPU使用率:top、pidstat 5等。
- 查看CPU运行队列长度、不可中断进程数:vmstat 5的r、b列